알고리즘 문제를 풀다가 반복문을 이용해 문자열을 합치는 부분이 있었다. 간단한 문제여서 String으로 문자열을 합쳤었는데 다른 사람들의 풀이를 보니 StringBuilder로 문제를 풀었다. 해당 문제를 String과 StringBuilder로 풀어봤는데 속도 차이가 많이 나서 어떤 차이 때문에 그런지 확인해보려고 한다.
String으로 풀었을 때StringBuilder로 풀었을 때
String
String은 불변(immutable)한 객체이며, 한 번 생성되면 내용을 변경할 수 없으며 길이가 정해져 있다. 이러한 특성 때문에 멀티스레드 환경에서 사용하기 적절하다.
public class TEST {
public static void main(String[] args){
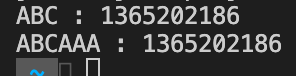
String str = "ABC";
System.out.println("ABC : " + str.hashCode());
str = "AAA";
System.out.println("AAA : " + str.hashCode());
}
}
위 코드는 동일한 str 변수이지만, ABC와 AAA를 가리키는 참조값이 다른 것을 확인할 수 있다.
위 결과에서 알 수 있는 것처럼, 문자열 조작(추가, 자르기 등) 시 새로운 객체를 생성해 조작된 문자열을 할당하고 기존 String 객체는 GC(Garbage Collection)에 의해 수거된다.
public class TEST {
public static void main(String[] args){
String str = "ABC";
System.out.println("ABC : " + str.hashCode());
str += "AAA";
System.out.println("ABCAAA : " + str.hashCode());
}
}
단, JDK 1.5 이상부터는 위와 같이 + 로 문자열을 합칠 경우 컴파일러 단에서 자동으로 StringBuilder로 변경해준다고 한다.
String 객체는 Comparable 인터페이스를 상속하고 있기 때문에 equals 메서드로 문장이 동일한지 확인 가능하지만 StringBuilder는 Comparable 인터페이스를 상속하지 않기 때문에 equals 메서드가 없으며 비교 메서드가 따로 존재하지 않는다.
새로운 String 객체를 만들고 값을 할당할 때 JVM(Java Virtual Machine)은 내부적으로 가지고 있는 string pool에서 같은 값이 있는지 확인한다. 같은 값이 있을 경우, pool에서 해당 객체의 참조값을 반환하며 값이 없을 경우엔 pool에 값을 생성한 후 참조값을 반환한다. 그래서 각 다른 String 객체에 같은 값을 할당하면 가리키는 값이 동일하며 똑같은 값을 두 번 할당하지 않기 때문에 메모리 또한 절약할 수 있다.
public class TEST {
public static void main(String[] args){
String str = "ABC";
String str2 = "ABC";
System.out.println("str : " + str.hashCode());
System.out.println("str2 : " + str2.hashCode());
}
}
StringBuilder/StringBuffer
StringBuilder는 가변(mutable)한 객체이며 내용의 변경이 가능하며, 내용을 변경할 경우 내부에서 내용의 길이를 변경한다. 이러한 특성 때문에 멀티스레드에서 사용하기에는 적절하지 않다.
public class TEST {
public static void main(String[] args){
StringBuilder sb = new StringBuilder("ABC");
System.out.println(sb.toString() + " : " + sb.hashCode());
sb.delete(0, sb.length());
sb.append("AAA");
System.out.println(sb.toString() + " : " + sb.hashCode());
}
}
동일한 sb 변수에 ABC값을 할당한 후 hashCode값과 sb 변수에 할당되어있는 값을 지우고 append() 메서드로 AAA 값을 할당한 결과 동일한 참조값을 가지고 있음을 볼 수 있다.
StringBuilder는 문자열 조작 시 새로운 객체를 할당하지 않으며 단순히 내부에서 문자열의 길이를 변경해 사용한다.
public class TEST {
public static void main(String[] args){
StringBuilder sb = new StringBuilder("ABC");
System.out.println(sb.toString() + " : " + sb.hashCode());
sb.append("AAA");
System.out.println(sb.toString() + " : " + sb.hashCode());
}
}
String에서 언급했지만 StringBuilder는 Comparable 인터페이스를 상속하지 않기 때문에 equals 메서드를 이용한 비교가 불가능하다. 따라서 아래와 같이 String 형식으로 변환 후 비교를 진행해야 한다.
public class TEST {
public static void main(String[] args){
StringBuilder sb = new StringBuilder("ABC");
StringBuilder sb2 = new StringBuilder("ABC");
if (sb.toString().equals(sb2.toString())){
System.out.println("sb, sb2 is equal");
}
else{
System.out.println("sb, sb2 is not equal");
}
}
}
String과 다르게 StringBuilder는 객체에 동일한 값을 할당하더라도 참조값이 서로 다름을 확인할 수 있다.
public class TEST {
public static void main(String[] args){
StringBuilder sb = new StringBuilder("ABC");
System.out.println("sb : " + sb.hashCode());
StringBuilder sb2 = new StringBuilder("ABC");
System.out.println("sb2 : " + sb2.hashCode());
}
}
StringBuffer는 StringBuilder와 사용하는 메서드가 같은데, 차이점이라면 synchronized 키워드가 존재하여 멀티스레드 환경에서 안전하다고 한다.
String vs StringBuilder/StringBuffer 성능 비교
동일한 문자를 100만 번 반복했을 때의 속도를 비교해보자.
public class TEST {
private static final int REPEAT_COUNT = 1000000;
public static void main(String[] args){
long start, end;
start = System.currentTimeMillis();
StringAppend();
end = System.currentTimeMillis();
System.out.println("StringAppend : " + (end - start) + "ms");
start = System.currentTimeMillis();
StringBuilderAppend();
end = System.currentTimeMillis();
System.out.println("StringBuilderAppend : " + (end - start) + "ms");
start = System.currentTimeMillis();
StringBufferAppend();
end = System.currentTimeMillis();
System.out.println("StringBufferAppend : " + (end - start) + "ms");
}
public static void StringAppend(){
String str = "";
for(int i=0; i<REPEAT_COUNT; i++){
str += '!';
}
}
public static void StringBuilderAppend(){
StringBuilder sb = new StringBuilder();
for(int i=0; i<REPEAT_COUNT; i++){
sb.append("!");
}
}
public static void StringBufferAppend(){
StringBuffer sb = new StringBuffer();
for(int i=0; i<REPEAT_COUNT; i++){
sb.append("!");
}
}
}
결과에서 확실하게 알 수 있듯이 String을 + 문자로 계속 추가하게 되면 객체의 생성, 삭제가 계속해서 발생하게 되며 GC가 개입하기 때문에 단순히 문자열을 연결할 경우 속도면에서 매우 불리하다. 그리고 StringBuffer를 이용한 값이 StringBuilder보다 조금 더 오래 걸리는데, 그 이유가 StringBuffer는 내부적으로 thread-safe 를 유지하기 위해 별도의 작업을 진행하기 때문에 시간차이가 난다고 한다.
public String solution(String[] participant, String[] completion){
String answer = "";
HashMap<String, Integer> hm = new HashMap<String, Integer>();
for (String string : participant) {
if (hm.get(string) == null){
hm.put(string, 1);
}
else{
hm.put(string, hm.get(string) + 1);
}
}
for (String string : completion) {
hm.put(string, hm.get(string) - 1);
}
for (Map.Entry<String, Integer> entry : hm.entrySet()) {
if (entry.getValue() != 0){
answer = entry.getKey();
break;
}
}
return answer;
}
hash를 이용한 풀이
효율성 테스트를 보면 메모리 양은 비슷하지만, 시간을 비교했을 때 상당한 시간 차이가 발생했었다. 내가 사용한 Arrays.sort 메소드는 내부적으로 TimSort 알고리즘을 사용하는데, 이 알고리즘은 Merge Sort 알고리즘을 기반으로 작성되었으며, Insertion Sort 알고리즘과 Merge Sort 알고리즘의 결합 형태라고 한다.
이메일 주소 검증 - 이메일 주소는 대부분 test@test.com 형태로, 아이디 부분은 영문 대/소문자, @는 하나이며 주소에는 .이 하나 이상이 들어간다고 가정했다. 이 정보를 기반으로 패턴을 정의하고 검증하는 과정을 거친다. 더 자세하게 검증 패턴을 만들기 위해서는 직접 구현하거나 검색을 통해 패턴을 알 수 있다.
import java.util.regex.*;
public class 정규표현식 {
public static void main(String args[]){
String strPattern = "[a-zA-Z_0-9]+@[a-zA-Z_0-9-]+[.[a-zA-Z_0-9-]]+";
Pattern p = Pattern.compile(strPattern);
String email = "test_01@test.co.kr";
Matcher m = p.matcher(email);
System.out.println("이메일 검증 : " + m.matches());
}
}
결과
이메일 검증 : true
문자열 치환 - 문자열에서 패턴을 이용해 특정 문자열을 치환할 수 있다. 아래 예제는 . 이 2번 이상인 경우 . 한번으로 치환하는 코드이다.
위 <디스어셈블> 사진을 살펴보면 printf 함수 호출 후 call c_test.851014 와 같은 명령어를 실행한다는 것을 볼 수 있다. 그리고 명령어 오른쪽 코멘트 부분을 살펴보면 C_TEST.c:5 라고 되어있는데 이는 C_TEST.c파일의 5번째 줄을 의미한다. <테스트 코드>를 살펴보면 5번째 줄에 있는 코드는 Recursive() 함수를 재귀호출하는 부분임을 알 수 있으며 <디스어셈블> 사진 속 851014 주소로 가보면 아래와 같이 Recursive 함수로 점프하는 것을 알 수 있다.
<호출부분 확인>
즉, 실제 컴파일된 파일도 마찬가지로 내부적으로 위 <재귀함수의 동작 원리>의 그림대로 동작한다는 것을 알 수 있다. 그러나 위 코드를 실행시켜보면 잘 동작하다가 Stack overflow 오류가 발생한다.
<스택 오버플로우>
Stack overflow는 프로그램 내부에서 사용하는 스택(쉽게 말해서 특정 값들을 저장하기 위한 공간)의 크기보다 데이터가 많이 저장되어 발생하는 오류인데, 원인은 프로그램의 구조를 알면 이해할 수 있다.
위 <테스트 코드>를 이용해 간단히 설명하자면 프로그램은 함수(Recursive) 내부로 들어가게 되면 함수 호출 전 데이터들(함수의 지역변수, 호출이 완료되고 다시 돌아갈 주소 등)을 스택에 저장하게 되는데, 위 코드의 경우 함수가 종료되는 조건이 없기 때문에 무한루프를 돌게 된다. 따라서 계속해서 데이터들을 스택에 저장하게 되고 무한루프를 돌면서 저장된 데이터들의 크기가 일정 크기를 넘어가게 되면서 스택 오버플로우가 발생하게 된 것이다.
이러한 문제를 해결하기 위해서는 재귀함수엔 무조건 재귀함수를 탈출할 수 있는 조건이 있어야 한다. 그 코드는 아래와 같다.
<테스트 코드2>
위 코드를 간단히 설명하면 if (n == 0) 의 조건과 Recursive 함수의 파라미터로 n값을 받도록 코드를 수정하였고, 따라서 5번만 Recursive Call을 실행한 후 동작이 완료된다.
<실행결과>
위 <테스트 코드2>를 직접 비주얼 스튜디오에서 디버깅하면서 확인해보면 쉽게 알 수 있다.
여기서 "시간"은 정확히 몇 초 걸린다! 그런 의미가 아닌 데이터의 증가에 따른 시간(연산속도)의 증가 정도를 의미
- 시간복잡도는 대입연산, 사칙연산, 비교구문, 함수호출 등의 연산을 기준으로 계산
- 시간복잡도는 최선, 평균, 최악의 경우로 나눌 수 있음
최선의 경우(빅-오메가, Big-Ω)
- 최선의 상황을 기준으로 시간복잡도를 측정 - 대부분의 알고리즘은 빅-오메가로 시간복잡도를 측정했을 때 만족할만한 결과가 나와 실제로 잘 쓰이지 않음. - 예를들어, 특정 배열을 탐색하는 알고리즘에서 찾고자하는 값이 첫번째로 있을 경우
평균의 경우(빅-세타, Big-θ)
- 평균적인 상황을 기준으로 시간복잡도를 측정 - 평균적인 상황이 무엇인가?에 대한 문제가 발생 - 간단한 알고리즘의 경우에는 구하기 쉽지만, 조금만 복잡해질 경우 경우의 수가 많아져 평균적인 상황을 구하기 어려움 - 빅-오 보다는 많이 쓰이지않지만 어느정도 쓰이는 것으로 보임 - 예를들어, 동전 하나를 100회 던졌을 때 앞, 뒤가 나온 횟수의 평균적인 상황, 앞, 뒤가 나올 확률이 무조건 50%인 상황 등
최악의 경우(빅-오, Big-O)
- 최악의 상황을 기준으로 시간복잡도를 측정 - 최악의 상황을 기준으로 측정을 하게되면 입력데이터의 개수가 많더라도 이정도의 성능은 보장한다는 뜻이 됨 - 대부분 알고리즘의 시간복잡도를 표현할 때 빅-오 로 표현함 - 예를들어, 특정 배열에서 탐색 알고리즘을 이용해 탐색할 때 찾고자 하는 값이 배열에 없을 경우
빅-오(Big-O) 표기법
- 단순히 시간복잡도를 표현한 다항식에서 최고차항의 차수가 빅-오가 된다.
- 예를들어, 100n^3 + 99999n^2 + 888 이라는 시간복잡도를 가진 함수가 있을 때, 이 다항식을 빅-오 표기법으로 표현하면 O(n^3)이 된다. 99999n^2도 상당히 큰 수인데 제외하는 이유는 단순히 시간복잡도는 위에 언급한 것처럼 데이터의 증가에 따른 시간(연산횟수)의 증가 정도를 표현하기 때문이다.
빅-오(Big-O) 표기법에 따른 계산방법
- 다음과 같은 코드가 있을 때의 시간복잡도를 빅-오로 표현하면 어떻게 될까?
for(int i=0; i<sizeof(arr)/sizeof(int); i++){
if (arr[i] == 7){
printf("7 => index %d\n", i + 1);
break;
}
}
배열 arr의 크기를 모르며 어떤 데이터가 들어있는지 모른다는 최악의 상황을 가정하고 구해보면 다음과 같다.
연산을 기준으로 시간복잡도를 구한다고 했으니
int i = 0 => 1회연산 i<sizeof(arr)/sizeof(int) => n회연산 i++ => n회 연산 arr[i] == 7 => n회 연산
이 된다. 따라서 위 코드의 시간복잡도는 T(n) = 3n + 1이 되며, 이를 빅-오로 표현하면 최고차항의 차수인 O(n)이 된다.
자료구조가 무엇인지 위키백과를 확인해보면 자료구조는 효율적인 접근 및 수정을 가능하게 하는 자료의 조직, 관리, 저장을 의미한다고 나와있다. 즉, 당연한 말이지만 위의 말 그대로 자료를 어떻게 구성(조직)할 것이고 어떤 방식으로 관리하고 저장할 것인지를 말한다.
자료구조는 알고리즘과 밀접한 관계를 맺고 있는데, 한가지 간단한 예를 들어보면 다음과 같다.
[예시] 반짝이가 일하는 편의점에 홈런볼 5박스가 들어왔는데 박스마다 유통기한이 다르게 들어왔으며 쌓여있는 순서도 유통기한 순서에 맞게 쌓여있는 것이 아니라 뒤죽박죽 섞인채로 쌓여있었다. 반짝이는 홈런볼 재고관리를 쉽게하기 위해 유통기한이 가장 길게 남아있는 박스를 아래에 쌓고 위로 쌓을수록 유통기한이 짧게 남은 박스를 올려두었고, 맨 위에 유통기한이 가장 짧게 남은 박스의 홈런볼부터 차례대로 매대에 진열해 놓았다. 진열된 홈런볼들이 다 팔릴때마다 한박스씩 맨 위에 쌓여있는 박스를 바닥으로 내려 홈런볼들을 꺼낸 후 진열하였다.
위 예시에서 홈런볼은 "자료"를 의미한다. 그리고 이 홈런볼들을 모아놓은 박스를 "조직"이라고 할 수 있다. 즉, 관련있는 것들(홈런볼)을 어떤 방식으로 구성(박스)할 것인지를 말한다. 그리고 유통기한 순서대로 홈런볼을 판매하는데 이것을 "관리"라고 할 수 있다. 이 박스들을 유통기한 순서대로 가장 길게 남은 박스는 아래에 두고 위로는 유통기한이 짧은 박스를 쌓아두는데 이 쌓아두는 것을 "저장"이라고 할 수 있다. 마지막으로 맨 위에 쌓여있는 박스를 바닥으로 내려 홈런볼을 꺼내는 행위를 "알고리즘"이라고 할 수 있다.
나중에 배우게 될 자료구조이지만 위 저장방식은 LIFO(Last-In First-Out)로 나중에 들어간 데이터가 먼저 나오는 자료구조인 스택을 이용하였으며, 알고리즘은 이 자료구조를 이용하여 어떻게 문제를 해결하는지를 말한다. 즉, 자료구조가 결졍되어야 그에 맞는 알고리즘을 결정할 수 있기 때문에 자료구조와 알고리즘은 밀접한 관계를 맺고 있다고 볼 수 있다. 물론 자료구조가 달라지면 알고리즘도 바뀌어야 한다. 위 예시에서 스택 자료구조가 아닌 큐(Queue) 자료구조가 쓰인다면 그에 맞는 알고리즘(맨 위의 상자를 아래로 내린 후 홈런볼을 꺼내는 행위)도 바뀌어야 한다는 뜻이다.